Last October's AWS us-east-1 outage was a reminder of what that costs when you don't have it. Half the internet went down for fifteen hours, taking roughly seventy-five AWS services with it. The teams that came through it cleanly had done the work to be active-active across regions. The teams that hadn't are still rebuilding trust with their customers.
Active-active is the floor. Real, worth it, and most teams haven't done it. But even with active-active in place, the failover is reactive (it kicks in after a provider is already failing), sessions still break during the region switch, and routing control is all-or-nothing. There's a layer above active-active where those gaps live. That's where Weavian sits: software intelligence applied to network routing, not more infrastructure.
This is the first in a series on how Weavian works in practice. We're rolling out the picture one piece at a time. Cloud side first, then traffic classification, then real-time path intelligence, then the security side. Today's post is on multi-cloud anchor portability: what it is, how it keeps sessions alive when a provider goes dark, and how it closes the gaps active-active alone leaves behind.
What anchor portability does
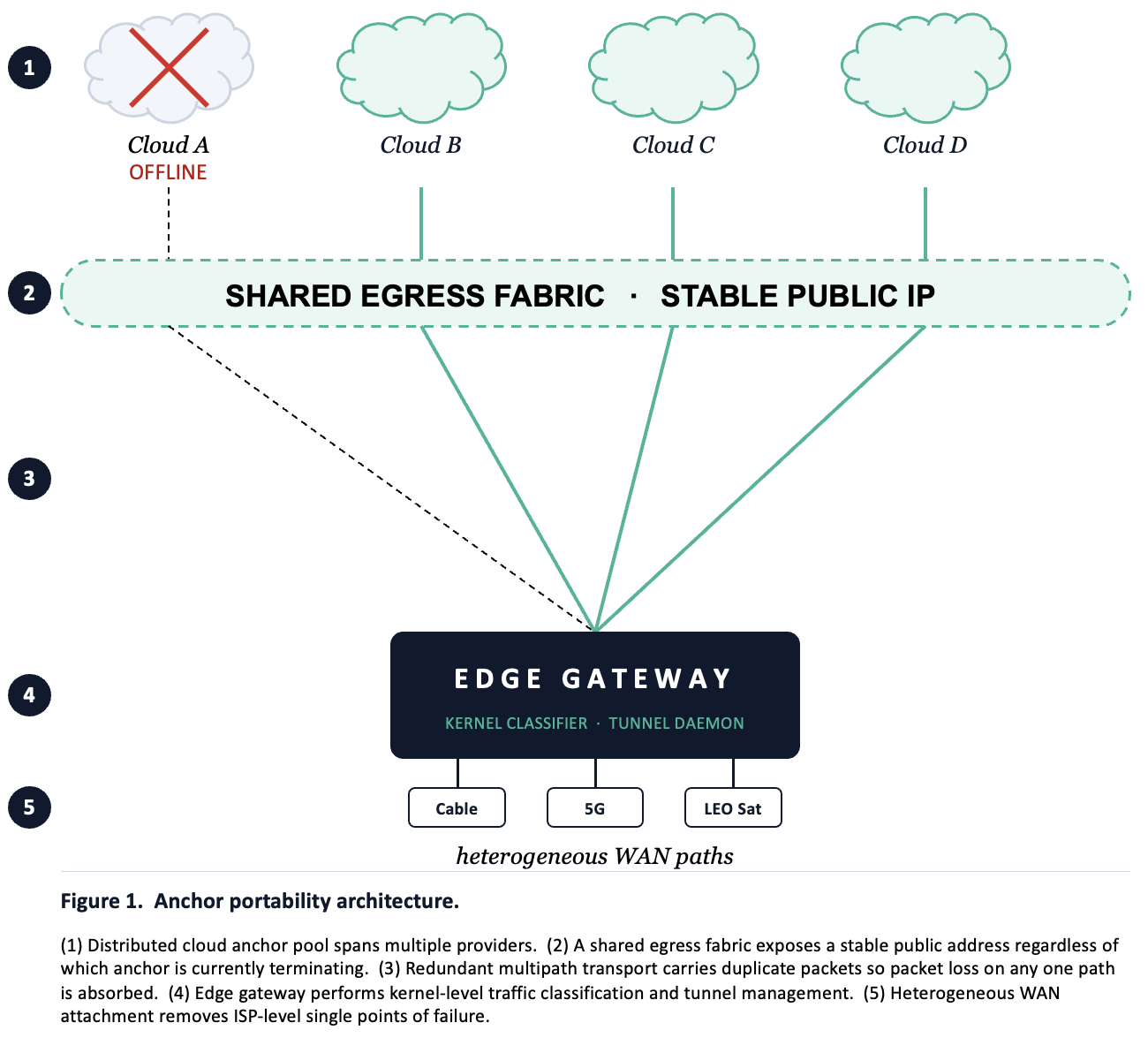
A pool of cloud anchors distributed across providers, sharing a stable egress identity. Traffic from the user's edge terminates at one of them at any given moment. When that anchor degrades or fails, the system shifts to a healthy one. The egress IP stays consistent because the anchors share an upstream fabric. The transport carries session state across the switch. The TCP connection, the WebSocket, the in-flight upload — all of those survive.
Two things make this work where active-active alone doesn't. The control plane reads link telemetry continuously and starts shifting traffic when degradation crosses early thresholds, not when failure does. Predictive, not reactive. And because the system understands traffic at a per-flow level, the shift can be granular: 20% of traffic instead of 100%, or one class of traffic while leaving the rest alone.
In practice, three things customers actually feel.
Real-time recovery.
A provider outage that would normally drop the connection and force a reconnect instead becomes invisible. Detection is sub-second. Failover is sub-second. The session keeps going.
SaaS allowlists keep working.
Many enterprise SaaS providers gate access on a stable egress IP. With portable anchoring, that IP doesn't change when traffic fails over between clouds. No firewall ticket. No lost access.
Operational continuity stops being a luck game.
When a cloud provider has a bad morning, your customers don't notice. The session keeps going. The dashboard stays connected. The upload finishes.
How the data plane works
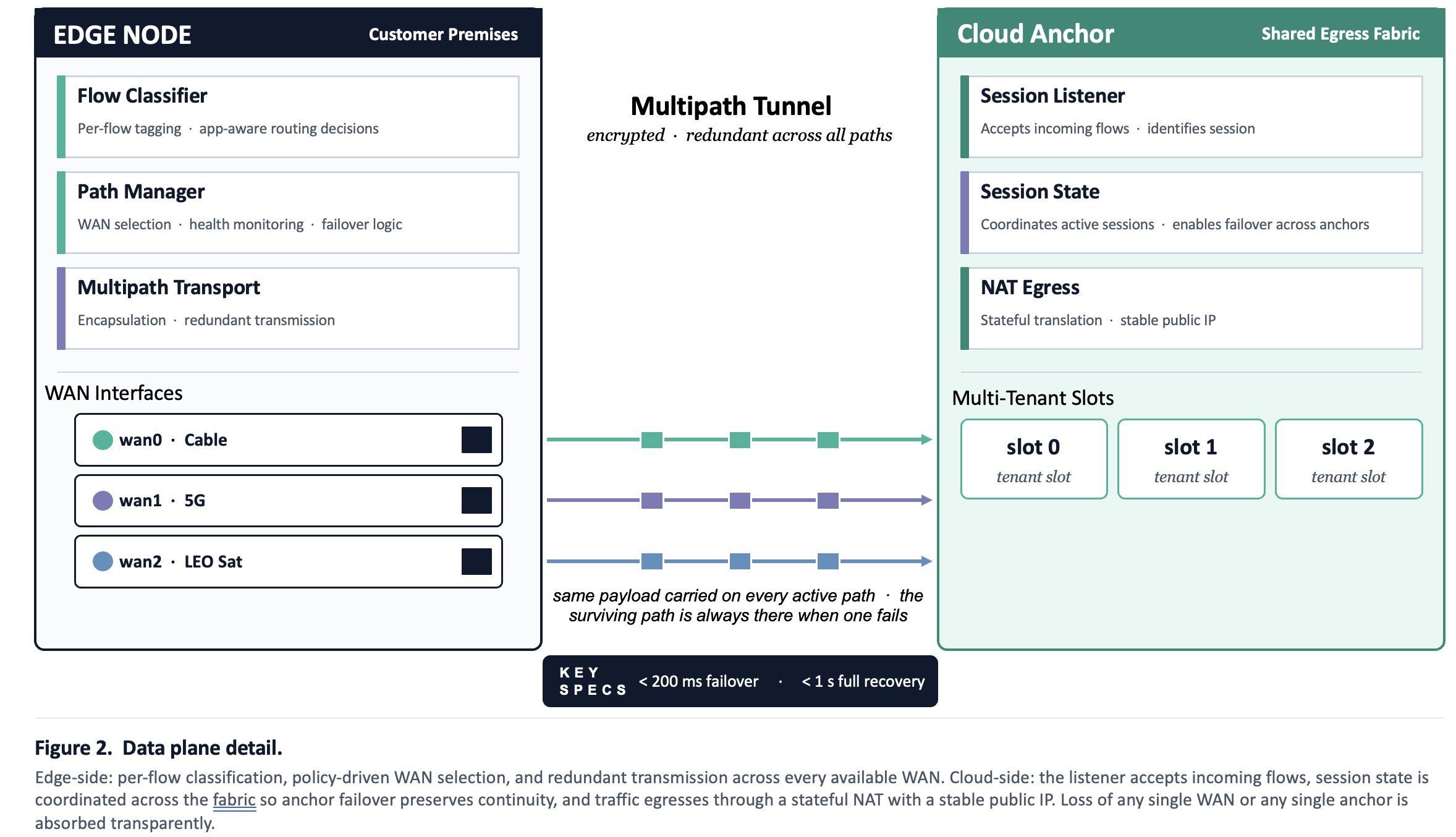
The edge classifies traffic per-flow and transmits the same payload across every available WAN. Cable, 5G, satellite, whatever's connected. At the cloud side, a session listener accepts the incoming flows, session state is coordinated across the fabric so anchor failover preserves continuity, and traffic egresses through stateful NAT with a stable public IP. The control plane uses predictive signals on link telemetry to detect degradation in sub-second windows and reroute before users notice.
Classify intelligently. Transmit redundantly. Fail over predictively. Egress stably. Four decisions, one outcome.
Why no one else does this
Enterprise SD-WAN products (Cisco, Palo Alto, Cato Networks) can absorb some of these failure modes, but they need a dedicated network team to configure and operate them. They're built for sites with twenty engineers, not five-person clinics or regional retail chains. Consumer multi-WAN products (Peplink, Speedify) bond ISPs for throughput but don't run a cloud anchor at all, so there's no portability story to tell on the cloud side. As far as we can tell, no one in the consumer or SMB segment ships portable cloud anchoring as a turn-key capability.
We do.
This is one piece. There's more to come.
Anchor portability is the cloud-side story. The rest of intelligent routing has a few more layers we want to talk through, one at a time. We don't want to dump everything at once because each of these has more depth than fits in a single post. A few we're likely to get into over the next few weeks:
- Selective traffic routing. Shifting a percentage of traffic to a different path, or rerouting one class of traffic while leaving the rest alone, in real time or as a planned shift. Enterprise ops teams do this all the time. We make it part of the routing fabric, not a manual operation.
- Predictive path selection. Spotting link degradation before it actually happens. Failover that starts before the failure does.
- Traffic awareness at the edge. Telling different kinds of sessions apart in real time, in under a millisecond, without inspecting payloads. Each routed according to what it actually needs.
- The security side. DDoS absorption, IP rotation, load balancing across paths. Things you get more or less for free once portable anchors and intelligent routing live in the same stack.
If your business depends on connectivity that can't drop,
get in touch.
We'll show you what this looks like for your environment.
Request a demo